I think of security relevant endpoint data within three domains: disk, memory and network. There are plenty of other taxonomies one could use. Disk, is generally addressed with File Integrity Monitoring (FIM). Memory, I am really talking about process execution, so anything that is exec’d and what it subsequently does (ie syscalls). Network, data transiting through external interfaces. Of course all three domains overlap - network configurations are stored on disk, sockets are opened with system calls, etc. There are also other useful optics like user identity and access that span these primitives.
To cover these areas on our production systems we look to the Linux audit framework. Audit provides two types of rule; file and system call. With these two primitives any other type of desired monitoring can be built. In fact ‘file’ is simply a wrapper on the open() syscall. In addition to system call monitoring, Linux system logging functions provide pre-built enrichments that correlate and present low level data in a more relevant format. For example auth.log should be captured, rather than trying to rebuild those events from syscalls yourself. The logging landscape in Linux is rather convoluted and evolving (ex. systemd-journald), so your configurations are likely to be distribution specific. We will stick to auditd in this post, but be aware there are many ways to collect this data.
Disk: monitor all files that contain credentials or configurations relevant to security, network or persistence. This will vary based on your own deployment as your application will likely have custom credential stores. For starters you can take the CIS Baseline which recommends auditing some key file resources. You should also look through you base image’s /etc directory for relevant configuration files you would like to monitor.
Memory: monitor all execve() system calls. This will catch any process launch, but we also must monitor for a few other events. If a ‘known’ executable is taken over by an attacker they could execute code within it without invoking execve, thus we look to guard against obvious injection techniques (ptrace). We also look for escalations and VM escapes with kernel module loads (f/init_module). Below is an example of an auditd entry for execve() of ausearch:
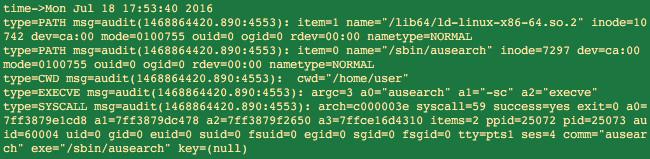
These messages can be verbose, so one can filter out auids for system processes. System processes will have uids within the reserved range and are lower risk (not no risk). The auid is consistent even when a user assumes another role, so sudo will not hide the originator.
Network monitoring can be quite expensive if you pursue full-take PCAP (ex. with tcpdump). Using auditd you can capture metadata just at the moments of truth: connect() and accept(), and maybe bind(). This metadata is generally enough, especially when paired with data obtained via network capture (VPC flow logs for instance in EC2) and used to link that to a process. Below we see curl establishing a socket, it turns out that it takes a few more steps to get an IP/port in order to correlate with VPC flow (more on that later).

Capturing application layer network activities is useful, but requires additional configuration. For example you could run a local BIND server and have nftables (iptables) forward all port 53 traffic to it to capture DNS requests, but this is brittle and better collected from the DNS server logs (at the closest resolver).
With auditd covering our three bases we have a good chance of catching adversary activity in our logs… the challenge is to recognize it as such and respond in a timely manner. Check out this basic set of audit rules to start playing with.