Last week we hosted colleagues from Google, AirBnB and Adobe to work on a joint effort to improve our disk forensics capability. Our goal is to move towards a streaming model for disk forensics by updating various existing tools that are built around the concept of imaging a single machine and creating a file. In a cloud environment we need to image multiple (even hundreds) of machines and process all those images into meaningful event data. Acquisition is fairly painless via API, but then what to do with the resulting snapshots?
We are working towards a cloud agnostic streaming service for disk forensics. To get there we are currently focusing on acquisition in AWS and then sending those snapshots through Plaso for processing, pushing results into ElasticSearch, which is then fronted by Timesketch for analysis. I filed a number of issues with Timesketch to move us towards this, and we are working with the Plaso maintainers as they do some refactoring as well, but even now, with a few hacks, we can compose a system that achieves our goals.
Acquisition
Currently we have a set of boto scripts that enables us (Netflix SIRT) to capture snapshots of a group of instances within AWS. This is a fairly straightforward process, and can even be done from the AWS console, but in our large multi-account multi-region deployment there are some manual steps to finding all the relevant instance-ids and regions and assuming into the right roles. To assist with this we leverage internal systems, like our open source Edda, and an aggregation layer in front of that called Locate. With this we can provide an instance-id and gather the data needed to target it. In addition this requires a forensics IAM role with the appropriate permissions in each account. We assume into that role from a dedicated forensic instance in a controlled management account, and then share the snapshot with the management account for processing.
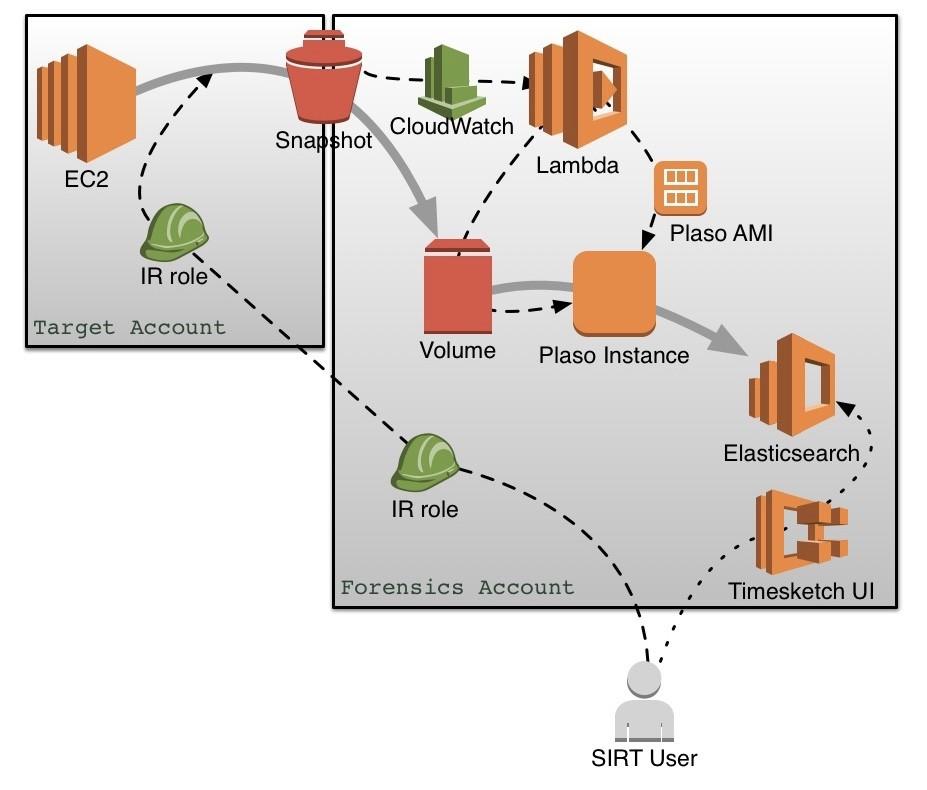
One area we are actively looking for collaborators is to take these scripts and generalize them for use with a native AWS deployment, rather than relying on Locate or other Netflix specific services.
Processing
Once the snapshot is turned into a volume in the management account it is ready to be processed. We need to deploy a Plaso instance in the correct availability zone to be able to attach the target volume. RECKLESS SHERPA is our process for detecting a newly available volume for processing and launching the appropriate instance with the target volume mounted as a secondary EBS. We can do this all in Lambda, but are also investing in our internal pipeline, the open source Spinnaker, for some of the benefits it provides.
The instances are launched from an AMI we create with a gradle file, packaged into a deb by Jenkins, and layered over our baseAMI by a service called Bakery. The deb package includes some systemd scripts that will run a wrapper script whenever a new volume is attached at certain mountpoints. This wrapper kicks off plaso against the mounted volume, using a collection filter specific to our Linux images. The next step we are building is for the wrapper script to send the resulting file to a Timesketch server which will load it into ElasticSearch.
In the future we hope to skip the file creation portion and stream events from Plaso as they are created directly into a hosted ElasticSearch. In order to do that we need some of the refactoring of Plaso to distribute file parsing across workers, and to make some slight tweaks to the way Timesketch sets up timelines based on ElasticSearch indexes. This work is in flight, but today’s work around seems viable.
Analysis
Timesketch will be our primary analysis platform to pull together multiple timeseries data sources and create a picture of what happened. We also would like to include events from the IR process for post incident reviews. For example we run most incidents in a Slack channel. If the crisis manager were to react to significant events with a slack emoji, we could export those messages into a time series and load them into Timesketch to overlay with event data from disk forensics and other sources.
If you are interested in collaborating on this effort please reach out: amaestretti@netflix.com